
Features Alpha Mind
Our program is a comprehensive solution for predicting stock prices by leveraging a combination of web scraping tools, data collection from the Reddit API, sentiment analysis, and machine learning techniques.
It aims to provide investors with valuable insights and enhance their decision-making process in the dynamic world of stock trading.
The program starts by using web scraping tools to gather data from a variety of financial news websites and Reddit.
This data includes news articles, comments, and posts related to specific companies and their stocks.
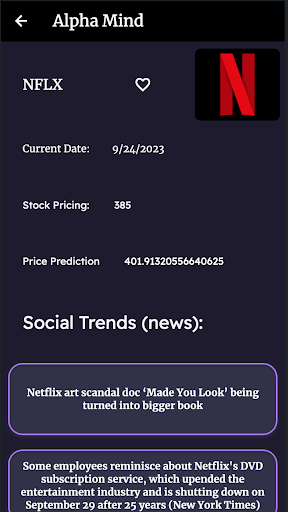
The cornerstone of our approach is sentiment analysis.
We employ Natural Language Processing (NLP) techniques to assess the sentiment of the gathered textual data.
By assigning sentiment scores (positive, negative, or neutral) to each piece of content, we can gauge market sentiment and investor sentiment toward specific companies.
This provides a crucial qualitative dimension to our predictive models.
With sentiment scores we get, we combine this data with historical stock price data.
Machine learning models, including the RandomForestRegressor, are then trained on this comprehensive dataset.
These models are designed to predict future stock prices, considering not only the numerical data but also the sentiment-related insights derived from Reddit discussions and news articles.
Learning Tools
Enhance your learning experience with interactive features.
Financial Tools
Manage your finances and track your expenses easily.
News & Updates
Stay informed with the latest news and updates.
See the Alpha Mind in Action

Get the App Today
Available for Android 8.0 and above